{kind=link}
{kind=link}
_-_image_1705670873910_0.png){kind=link}
_-_image_1705670919100_0.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
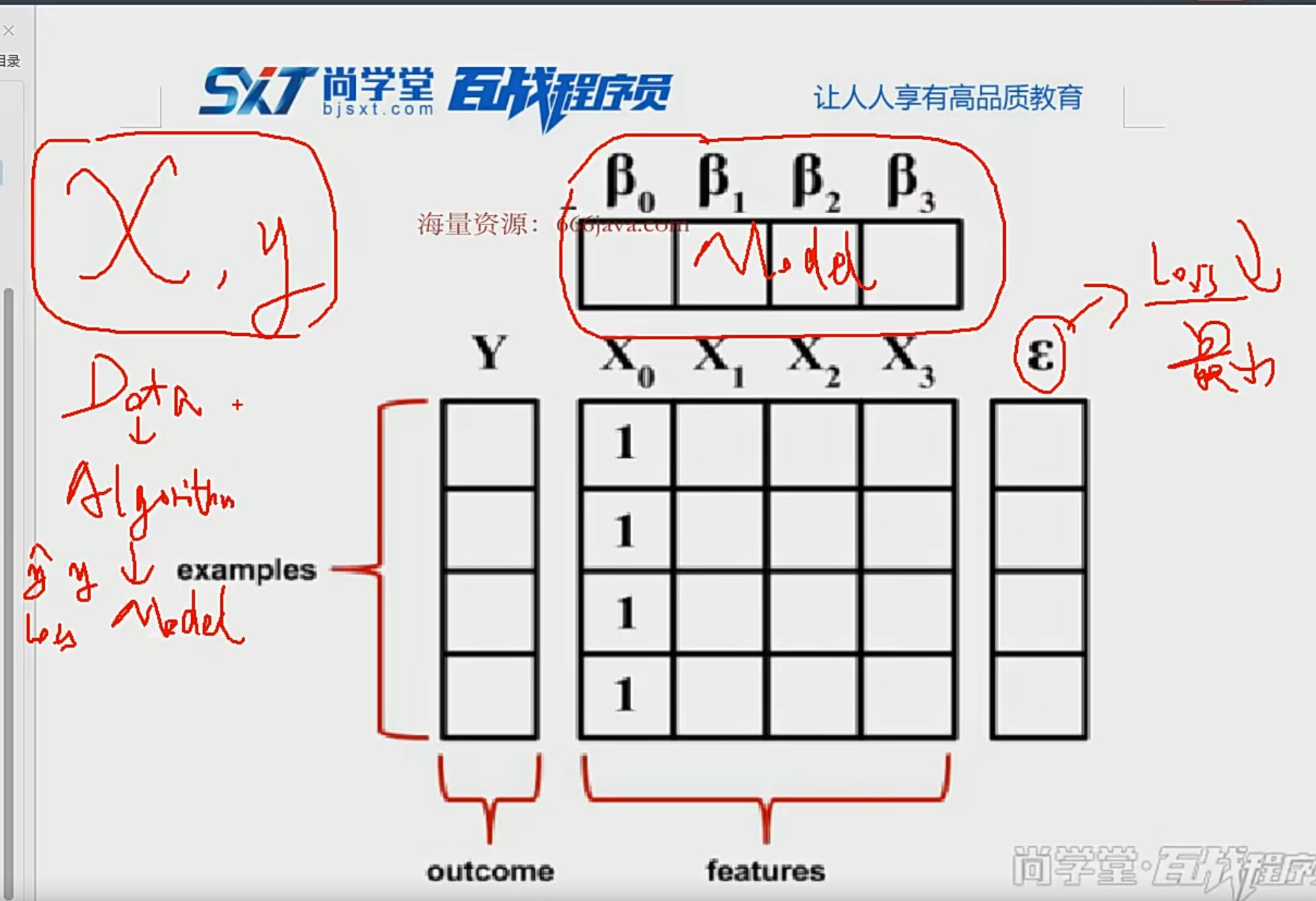{kind=link}
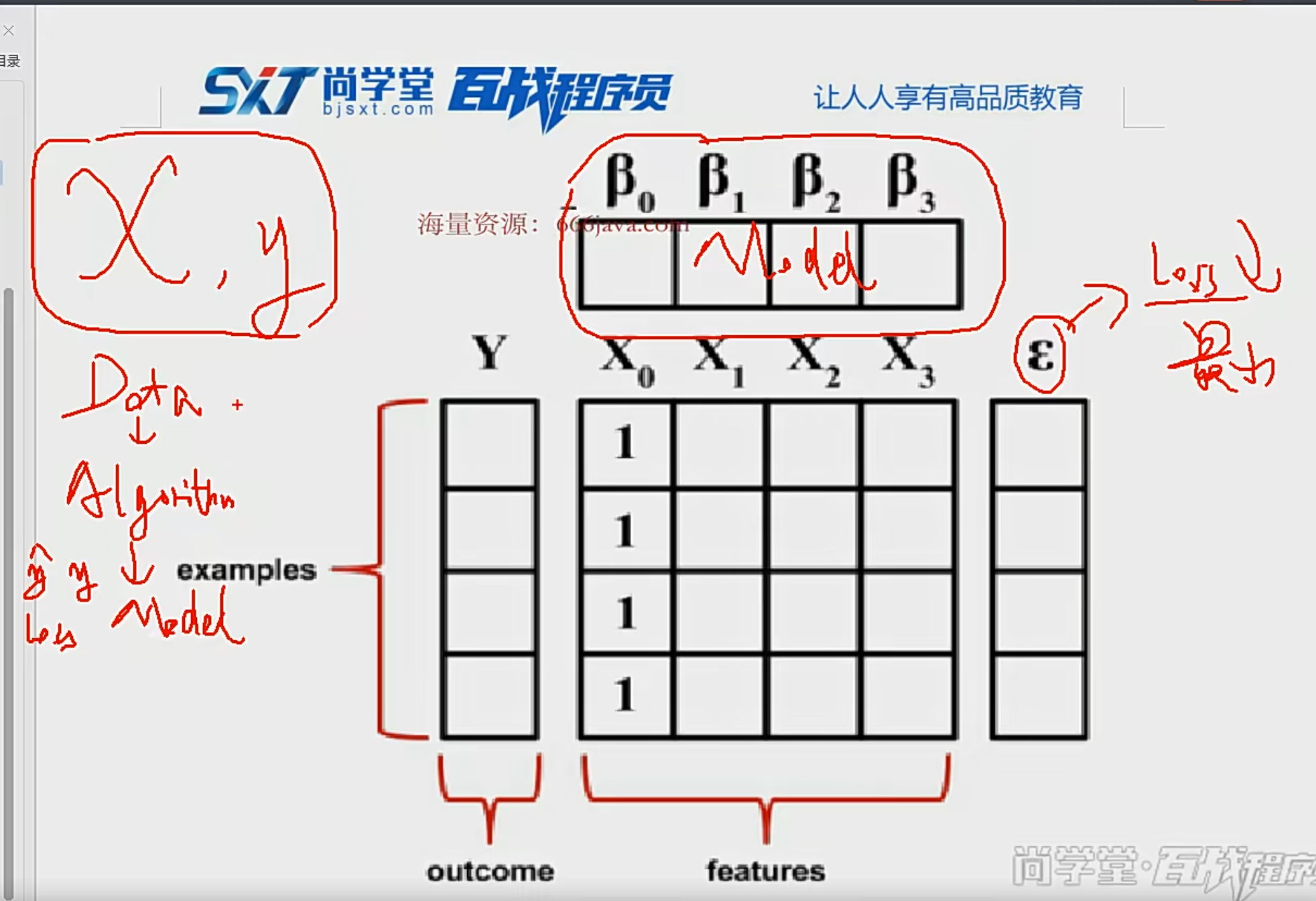{kind=link}
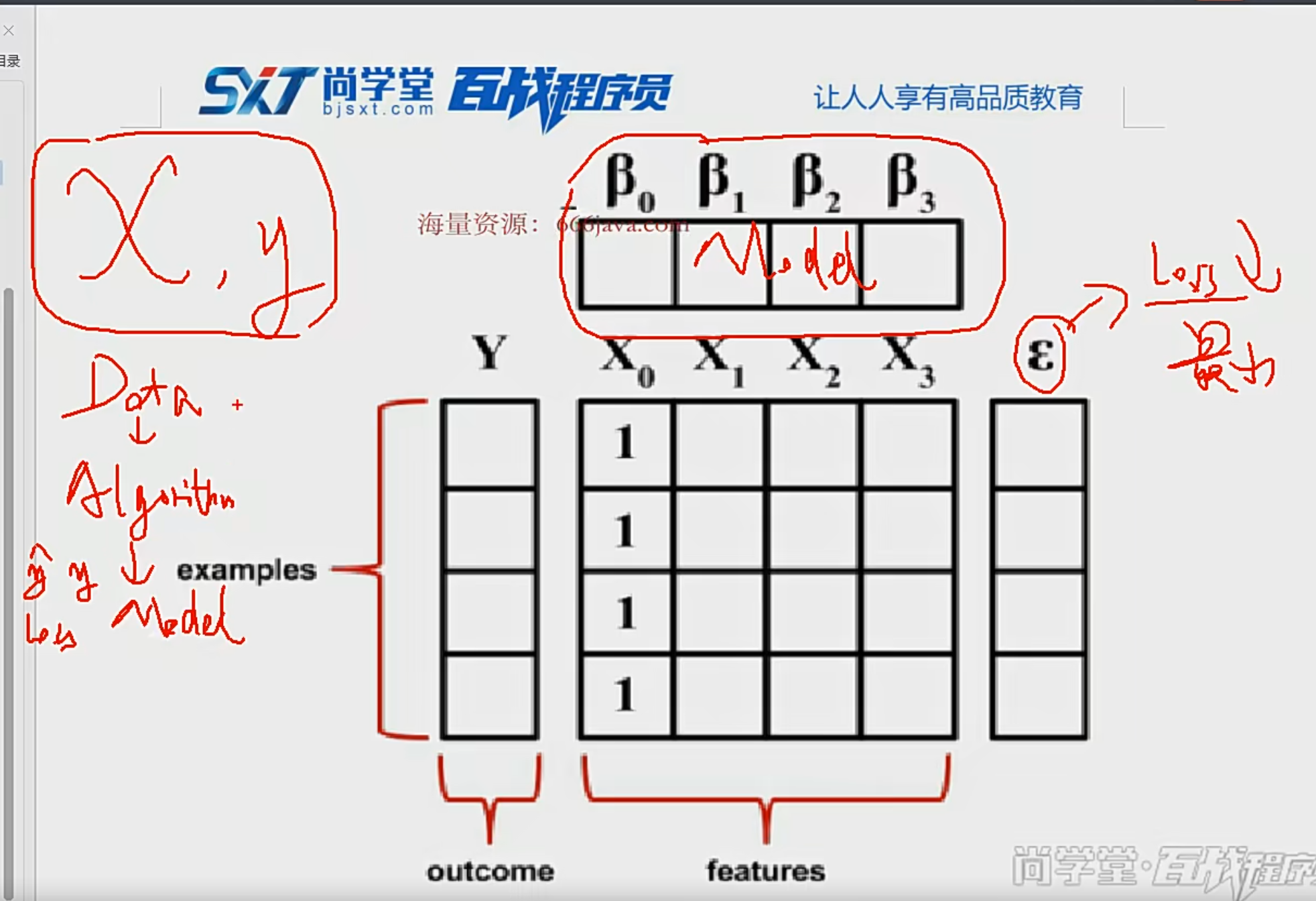{kind=link}
{kind=link}
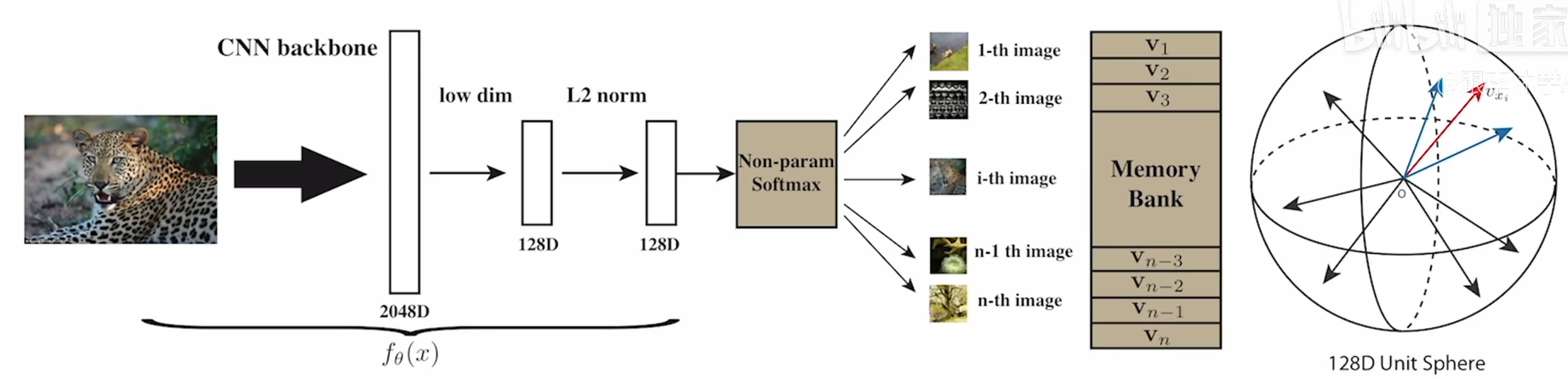{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
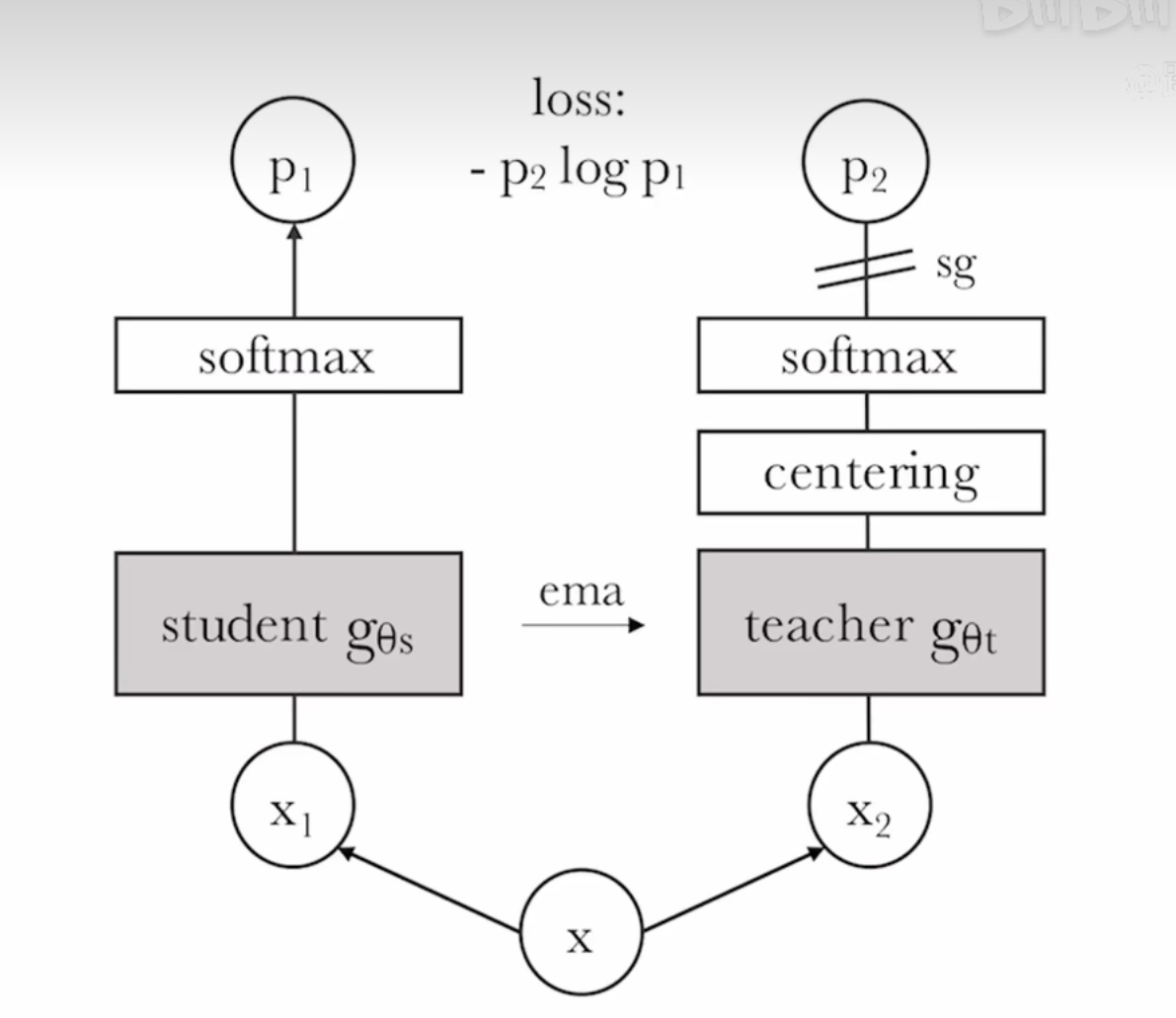{kind=link}
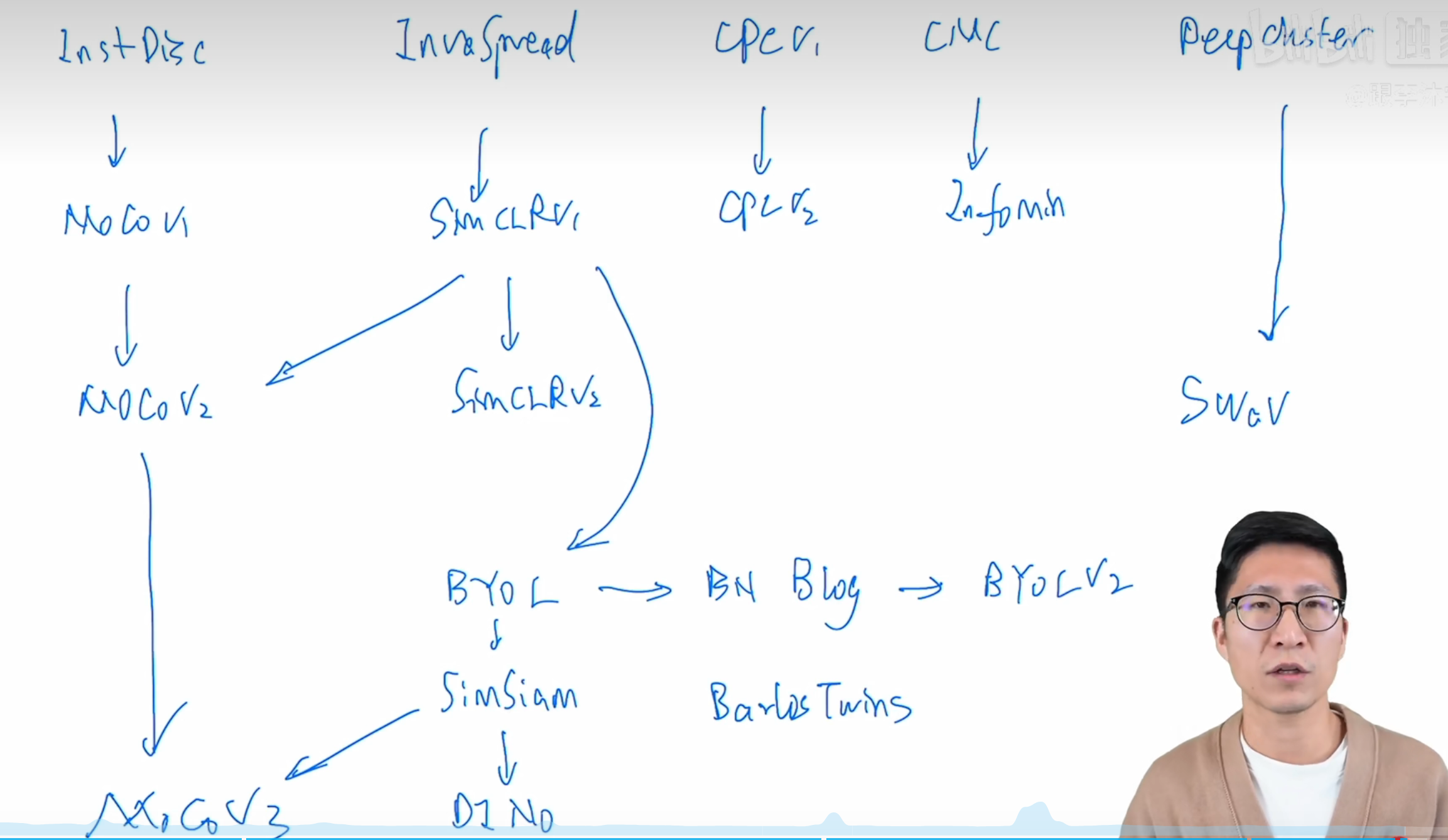{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
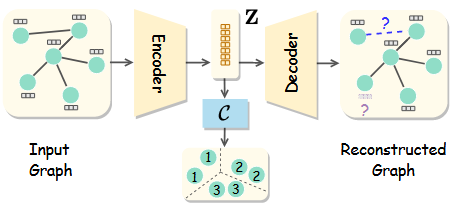{kind=link}
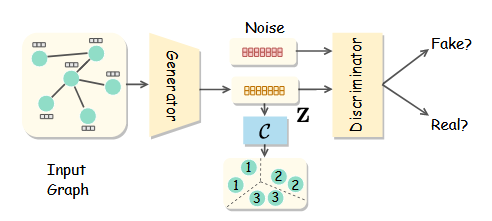{kind=link}
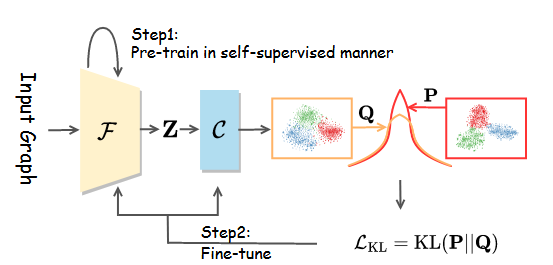{kind=link}
{kind=link}
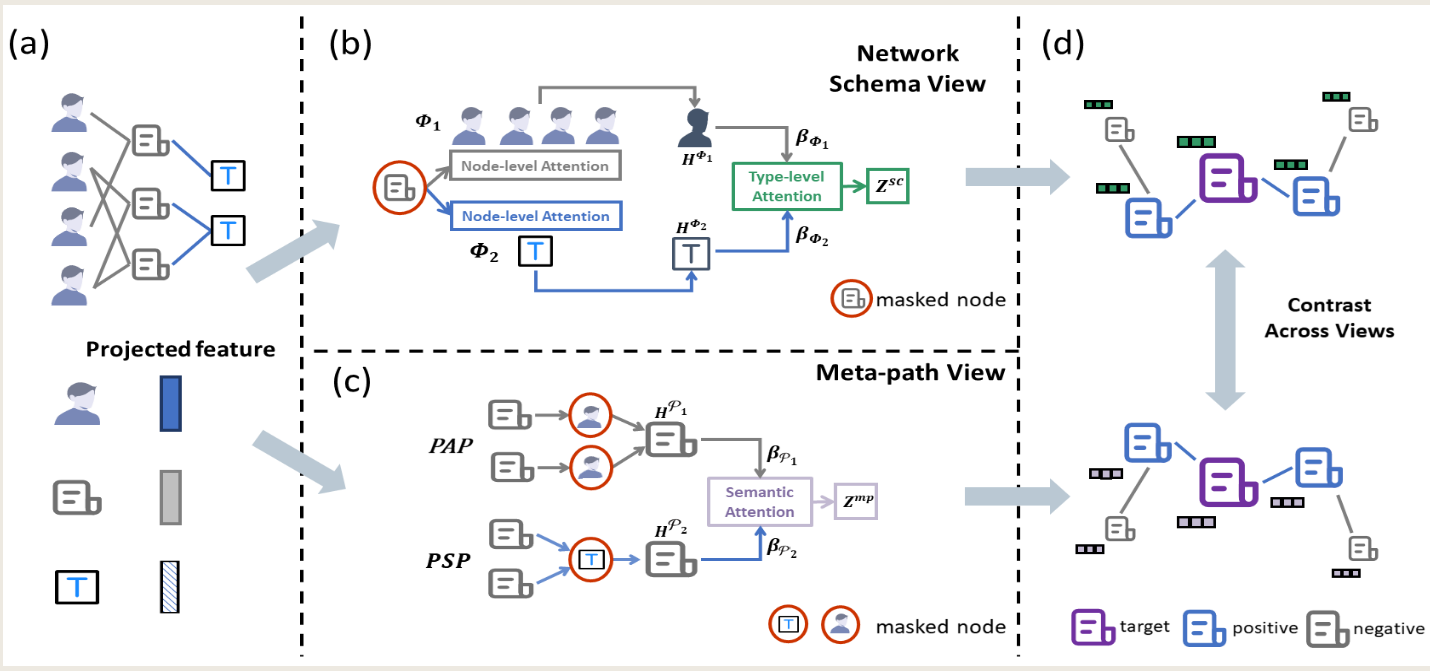{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
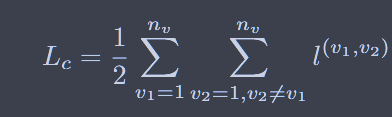{kind=link}
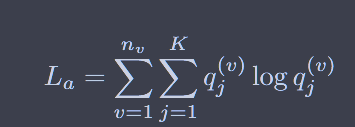{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
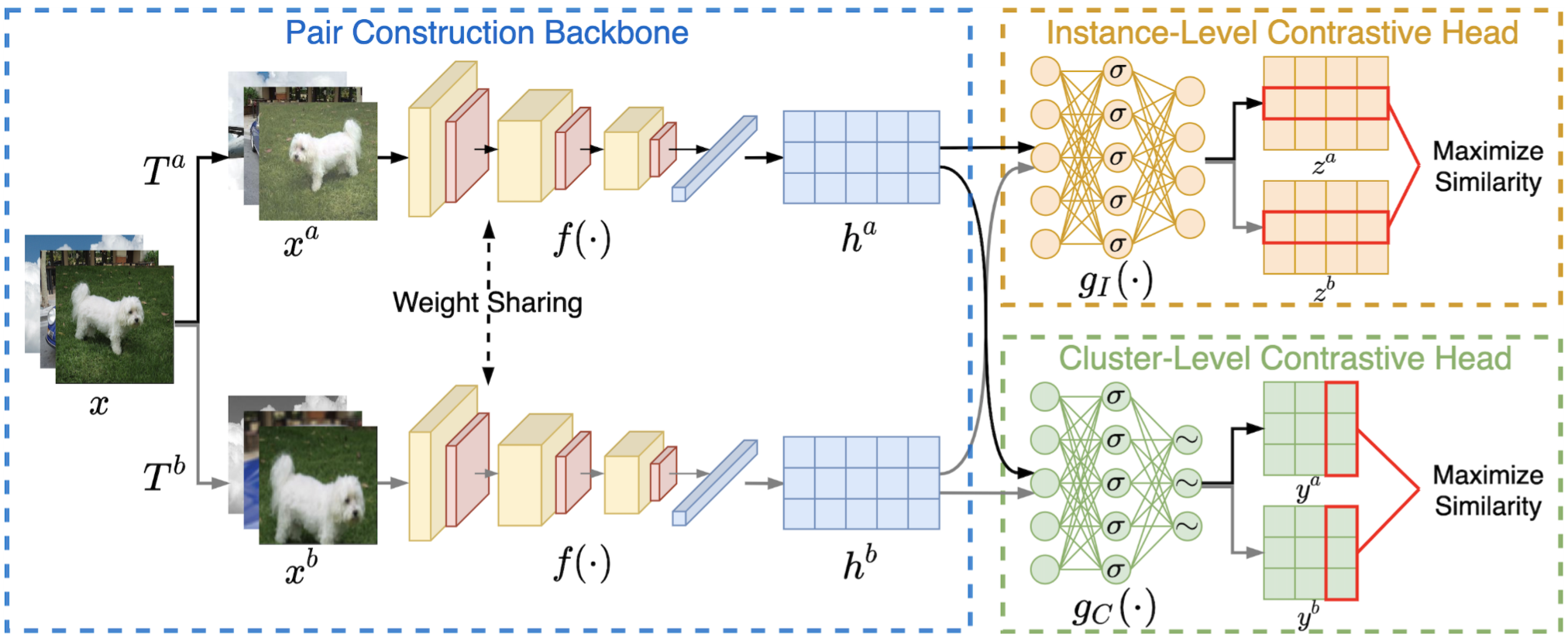
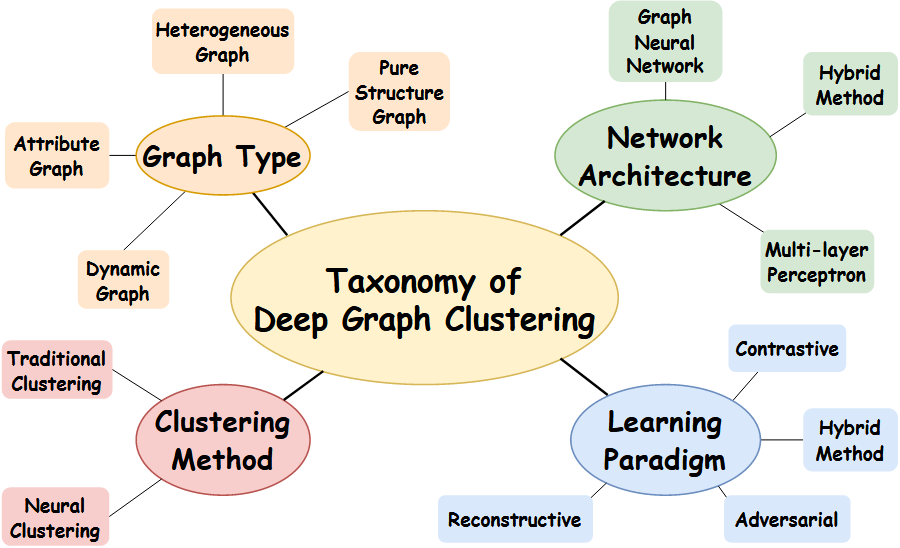
对比学习篇
对比学习本质?
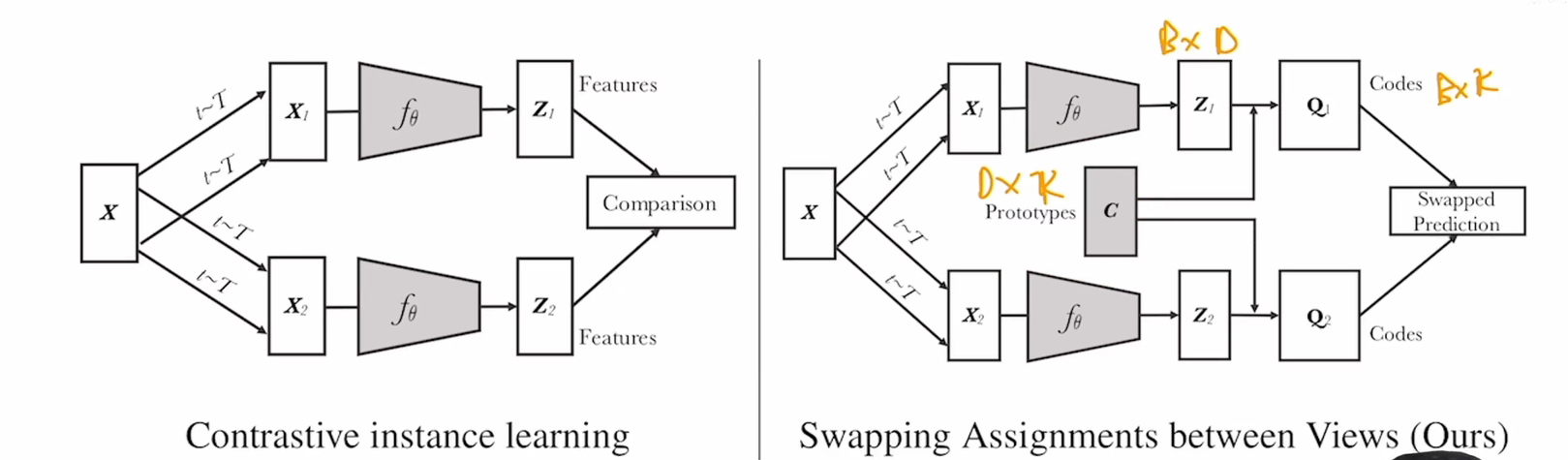
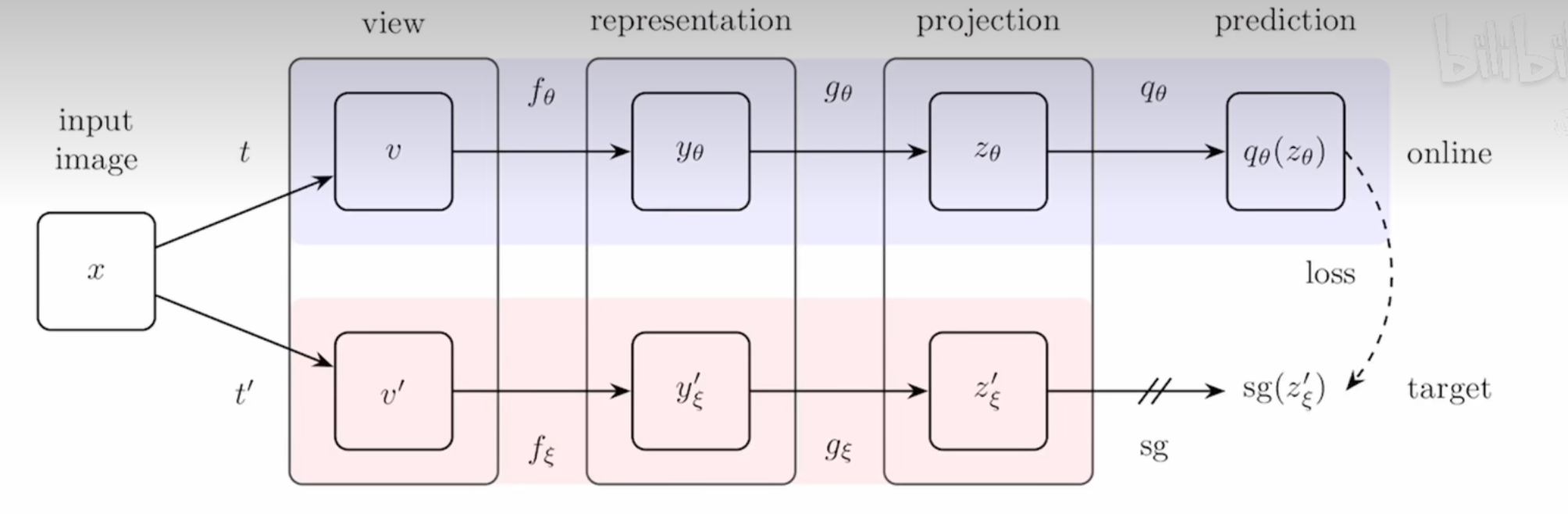
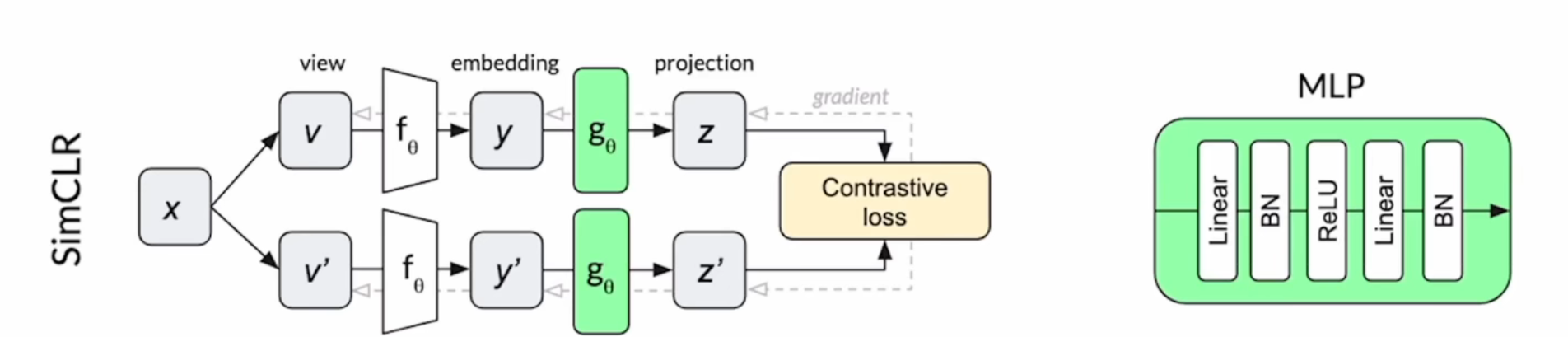
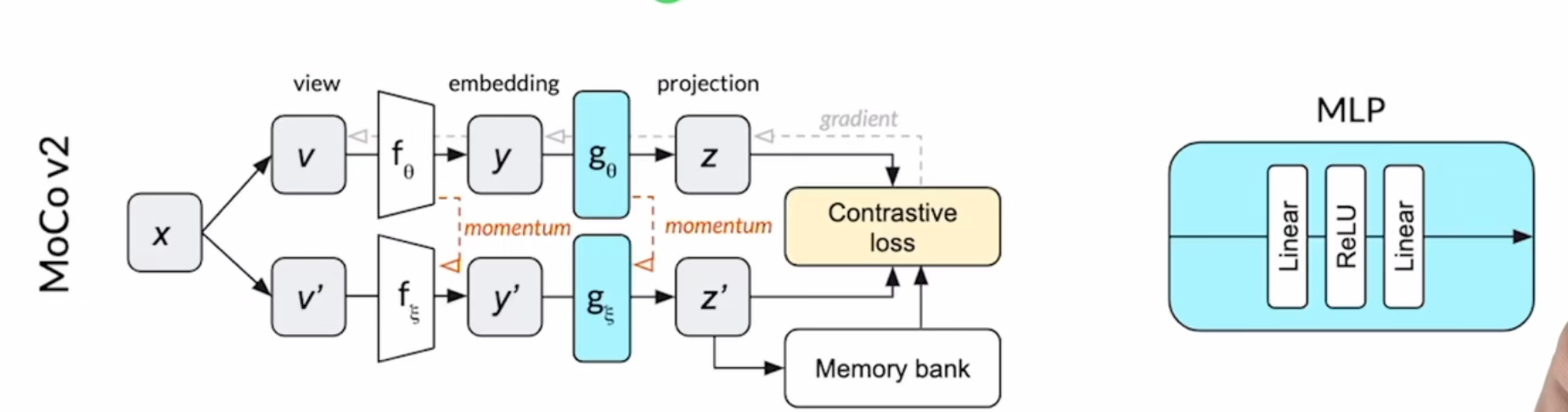
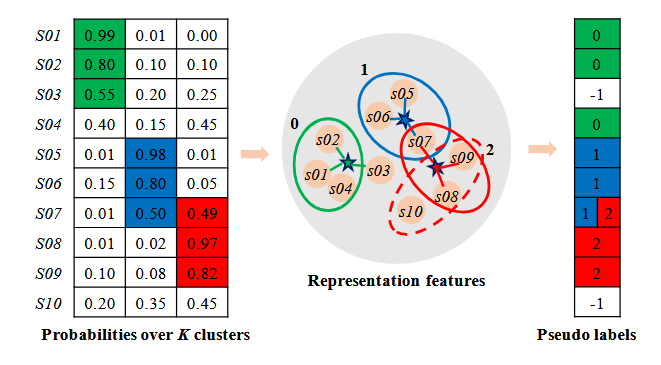
对比学习对节点的边进行了随机增广,并将两个相似的节点进行对比,从而在学习中更注重结构的信息
流派
传统
这是经典的infoNCE loss
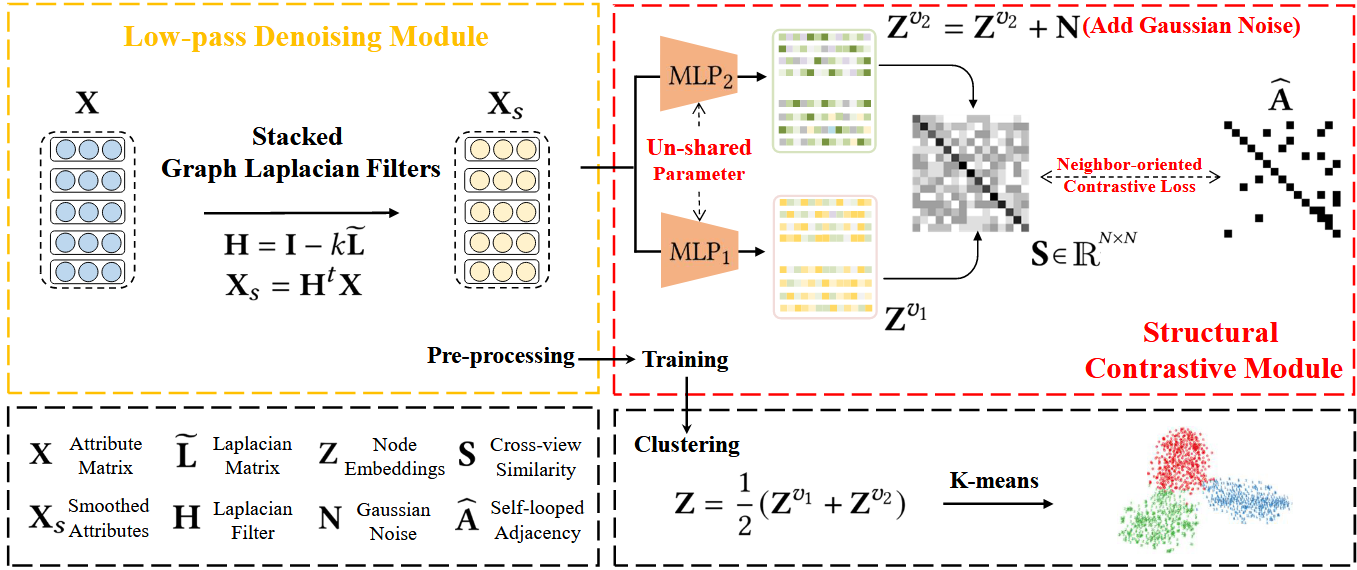
变种1
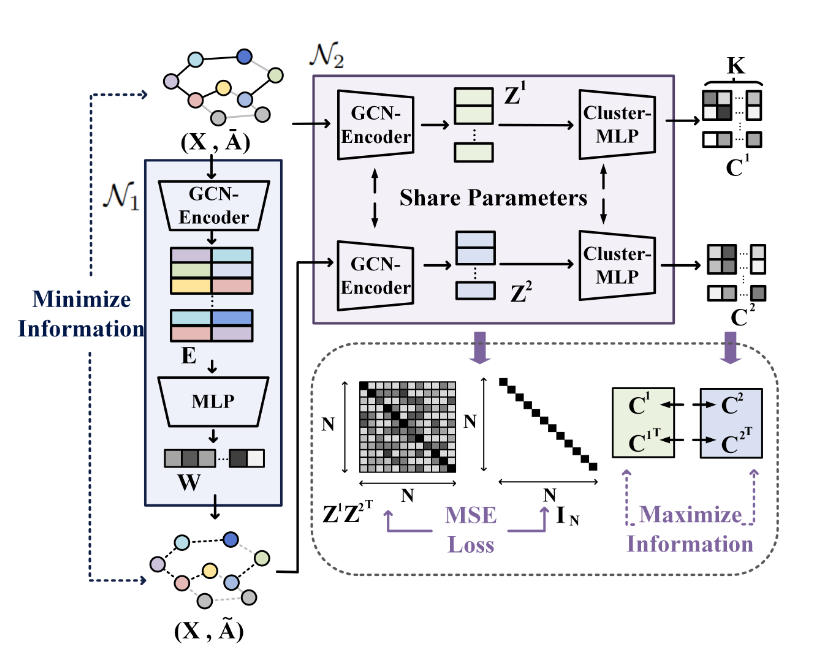
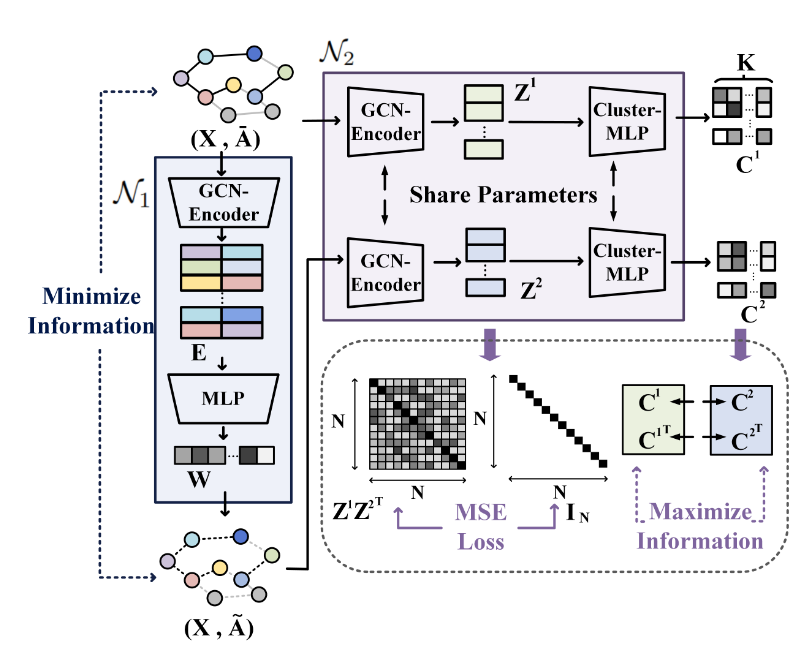
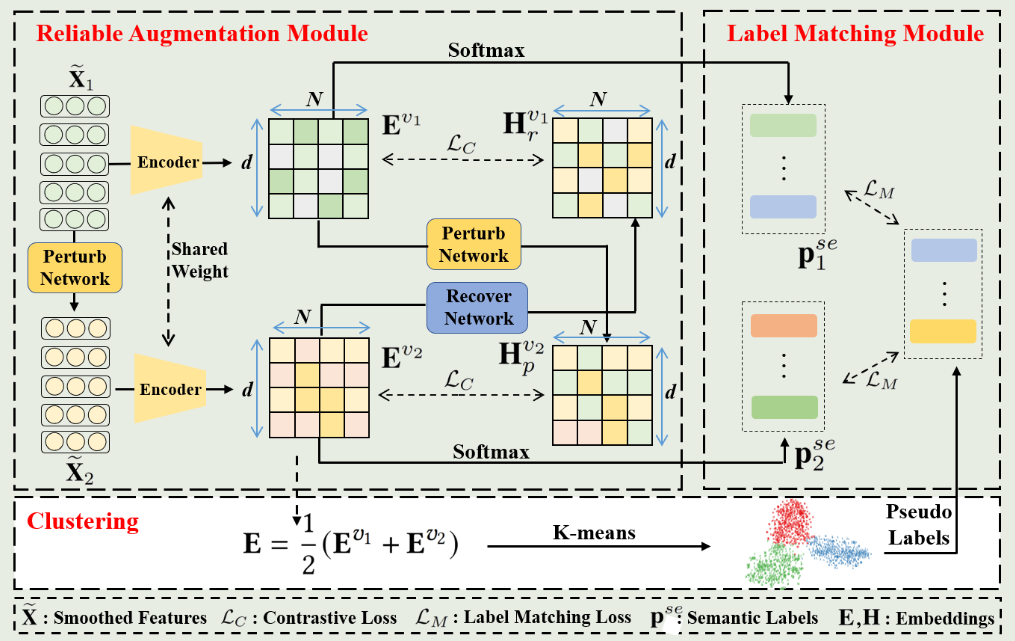
之后,liuyue突发奇想(SCGC),觉得这个比较的不是结构信息吗,因此我就改造一下,直接比较结构信息,看能不能取得好的结果(增广方式:高斯对得到的向量嵌入增广)
改造公式:

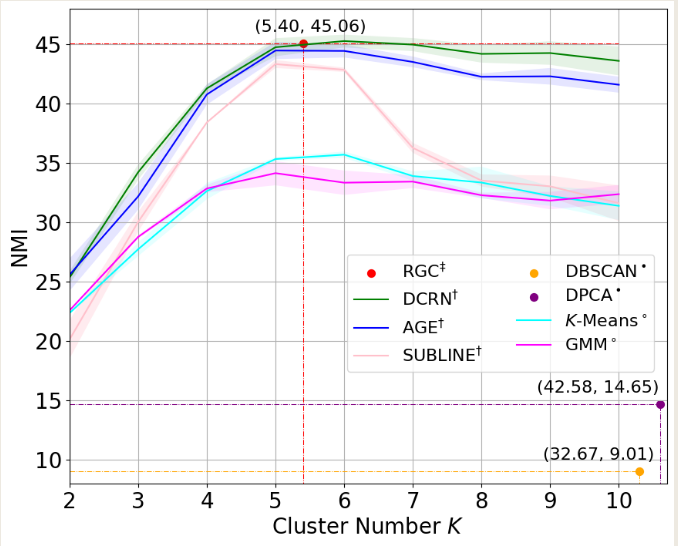
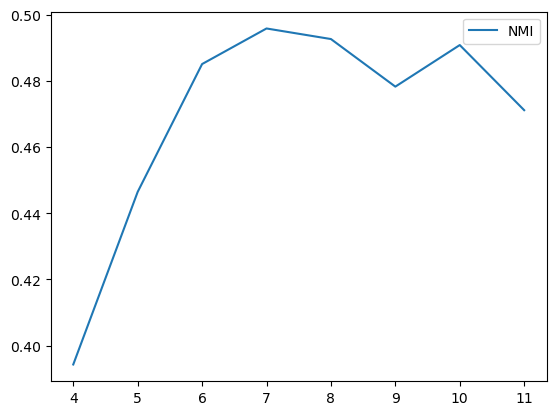
得到稳定的嵌入之后,接了一个kmeans,AMAP数据集上,NMI 67%
liuyue写的文章,消融实验做的非常好,值得我借鉴.
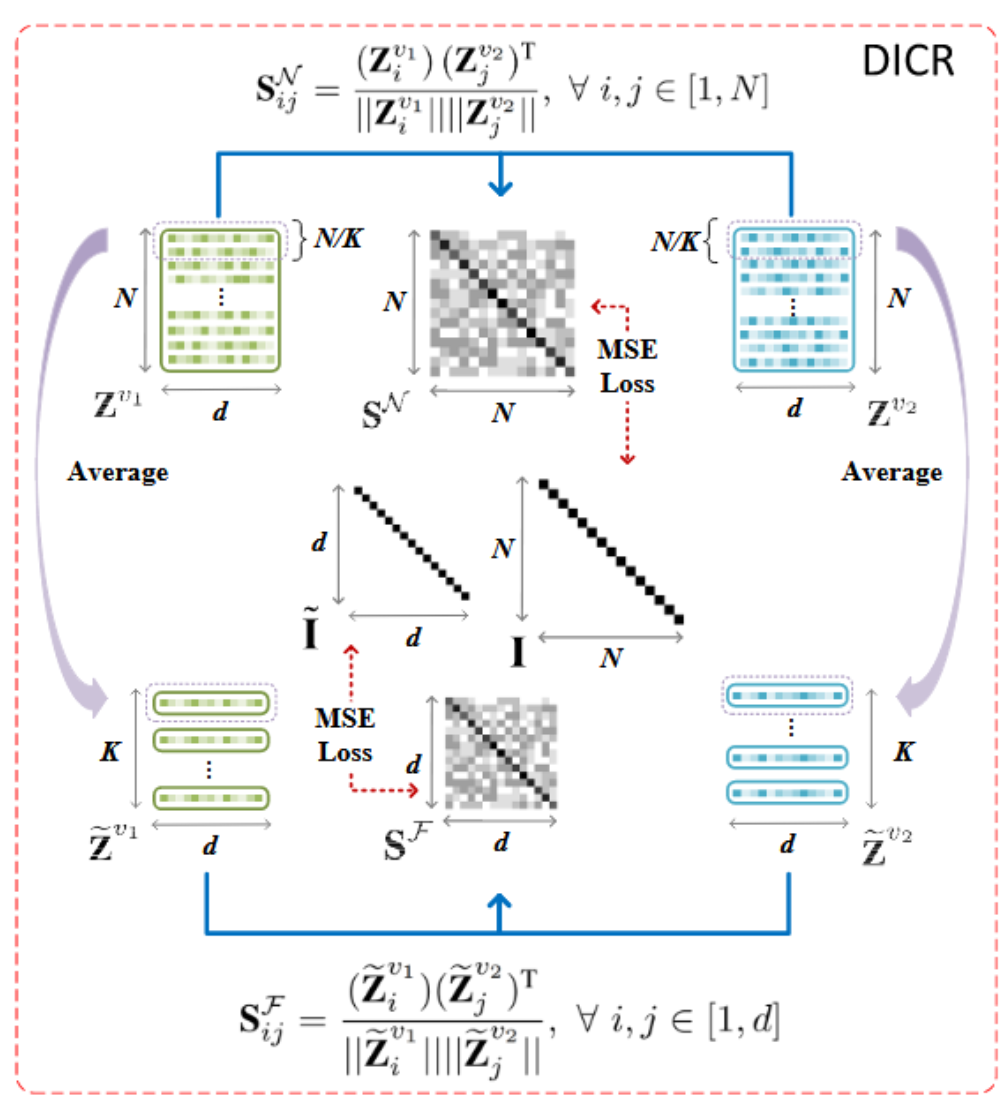
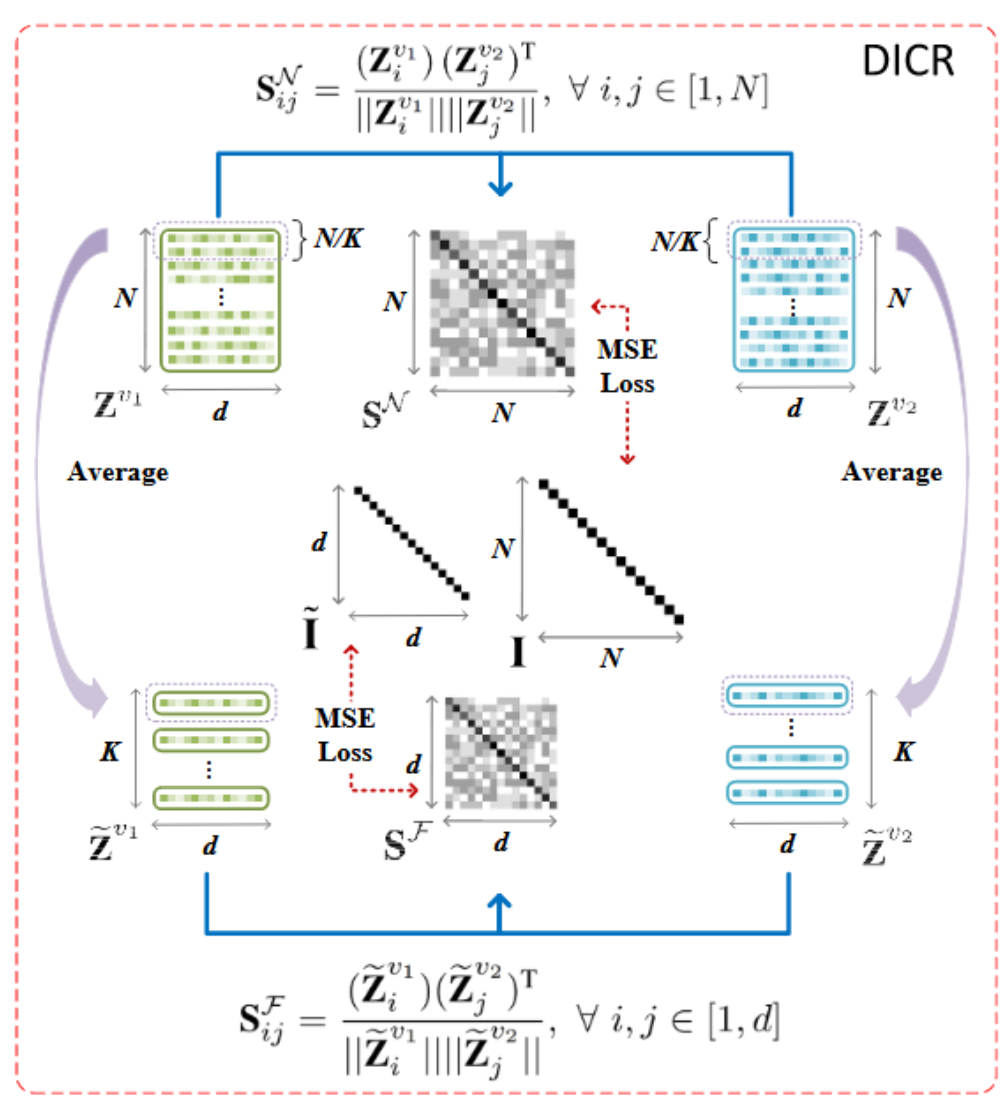
这篇文章的父亲辈的也是他们实验室写的Attributed Graph Clustering with Dual Redundancy Reduction
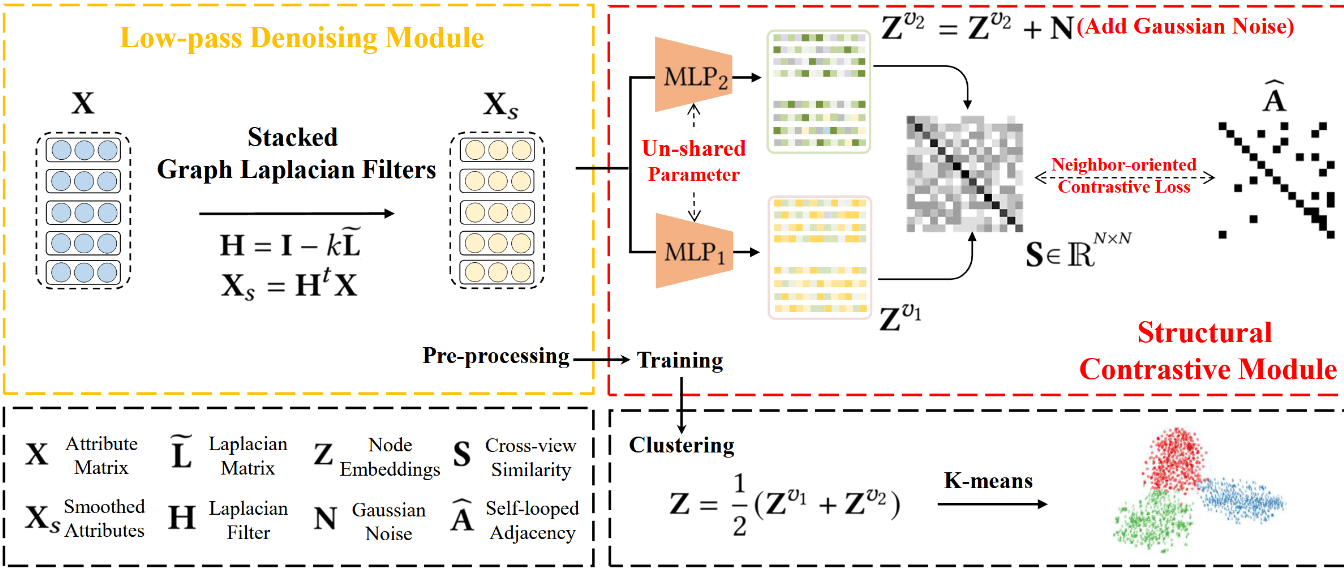
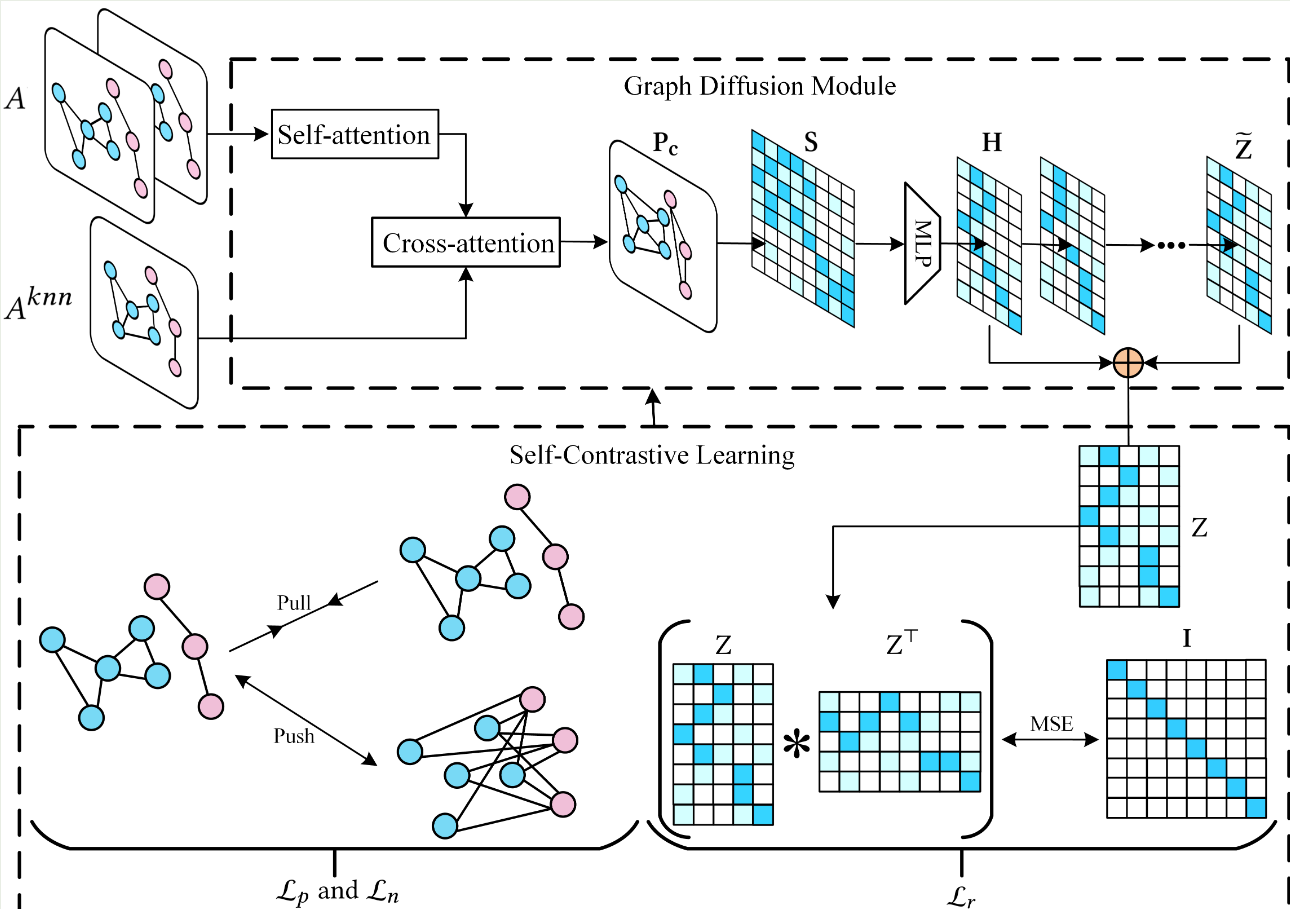
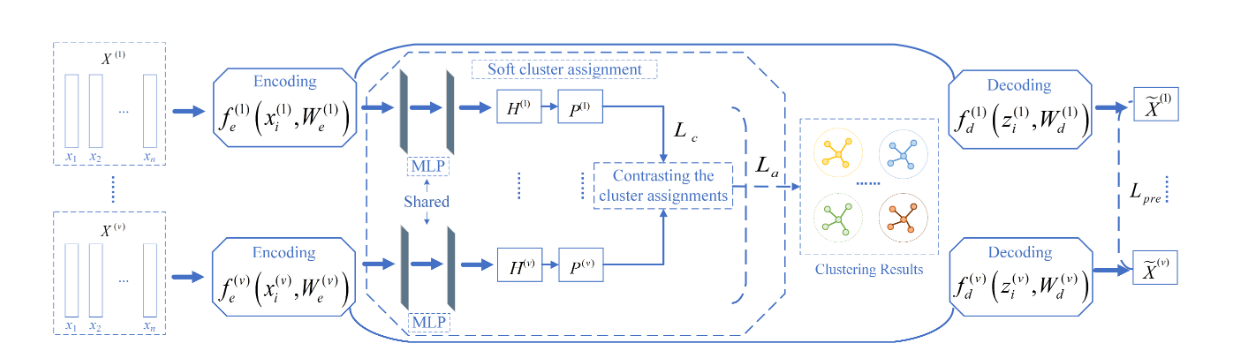
这篇文章,直接用得到的节点嵌入(邻接矩阵),去模拟邻接矩阵.具体方式是:加了一个sigmoid(MLP((Zi,Zj)),然后对邻接矩阵A进行加权
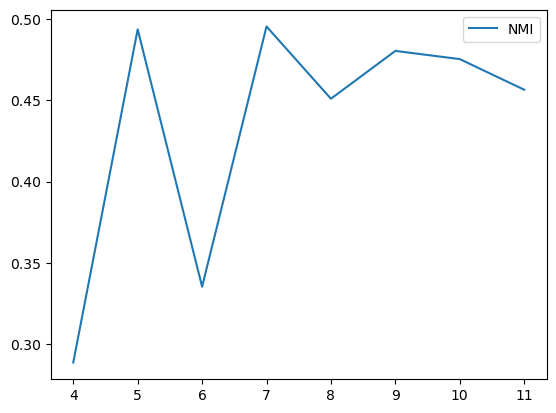
结果:AMAP NMI 72
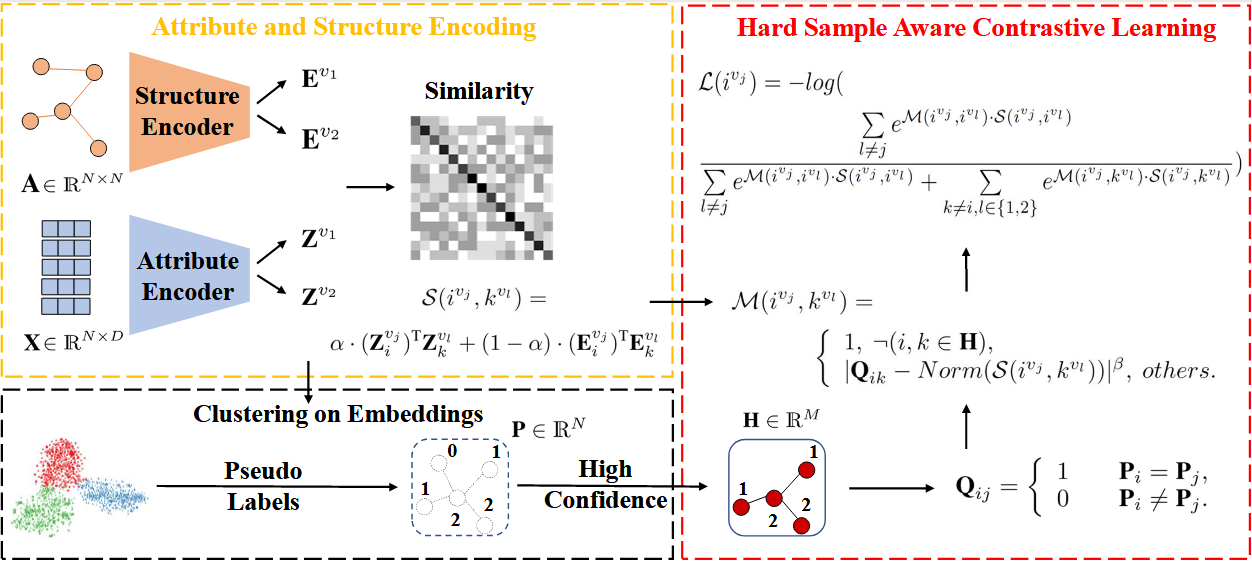
除此之外,这篇文章也用了对比聚类的方式,loss用MSE以及对比损失来操作.具体介绍:
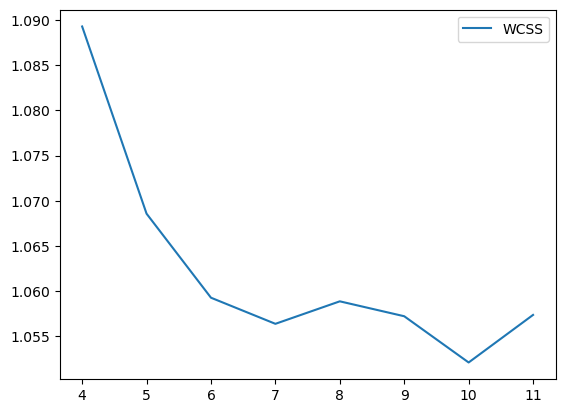
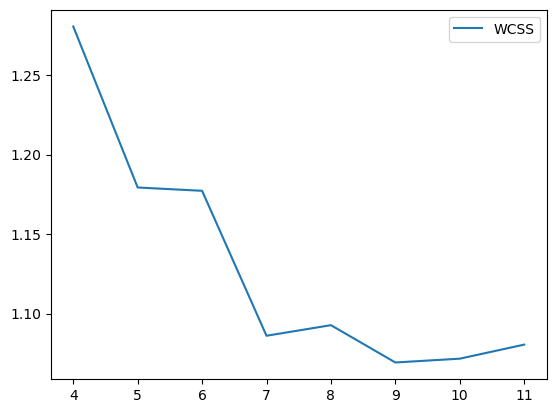
类级别对比损失,已相似性函数为对比对象,可以更好的保留类的轮廓.而MSE(WCSS),则保留了kmeans为首的以节点到聚类中心的平均距离为评价指标的优势.效果很好.

聚类效果:

总结:这两篇文章为啥能发出来?主流的文章是尝试将两个对比学习样本进行优化,来更好的获得结构与部分语义信息.但是,他们两个反其道而行,通过与邻接矩阵对比,来更好的获得结构信息.因此,文章可以发出来(即他们优化的是特征提取阶段,而不是特征对比阶段).但是,理论上他们的效果没有主流的对比方法好, 因为更多的只学到了结构信息
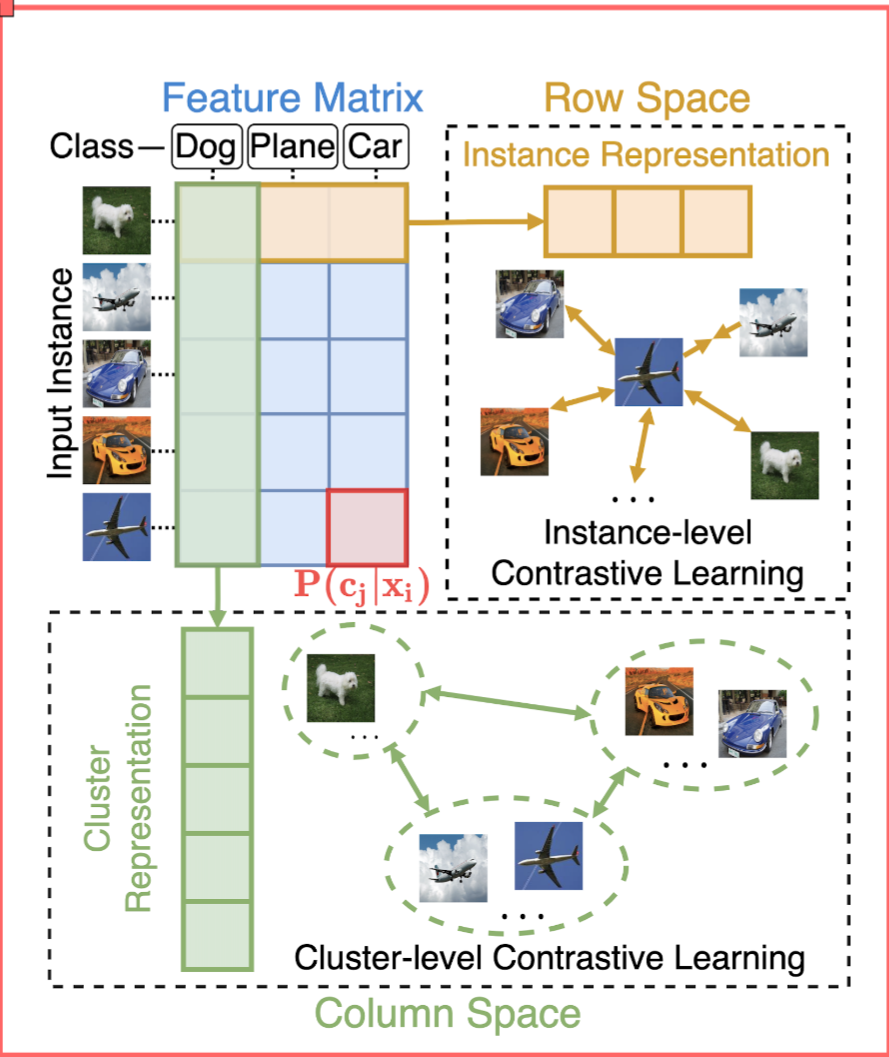
相似性矩阵杂谈
除此之外,他们还用相似性矩阵做hard sample cluster,Cluster-guided Contrastive Graph Clustering Network等,基本上思路一模一样的论文(真能水)
变种二
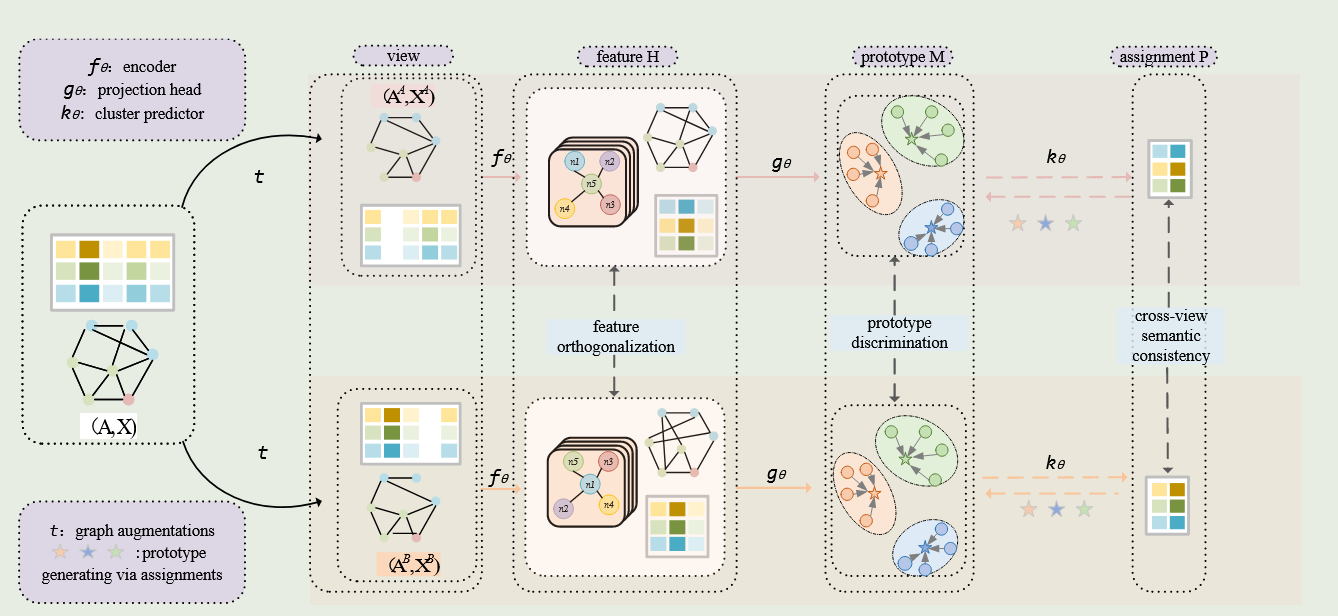
之后,很多人又提出了一种对比损失,他们指出,我可以单个向量单个向量对比,那么为啥不可以将向量的整合特征做出来进行对比呢?
介绍:Dink-Net(大图聚类)
因此,新的对比损失如下:
batch中有聚类中心损失,WCSS损失.另外一个新的损失:
第一个嵌入向量是
和Attributed Graph Clustering with Dual Redundancy Reduction差不多
理论对比:1.他使用的BCE将
2.他使用的kmeans优化,理论上比不过AGCD这一篇.因为他本质上只用了WCSS以及聚类中心距离信息,而没有使用聚类对比信息.在AGCD的消融实验中,验证了两者比单个的好.那么为什么agcd效果不理想呢?我的理解是:将相似矩阵和A进行对比,与对比损失重合了.(待做实验)
水文
DCRN 
另外一篇基本一样的论文:
DCLNGC(和DCRN基本上一模一样)
评判标准篇
聚类指标篇
WCSS,类中心距离
KL散度
对比聚类损失
对比标准篇
nce损失
barlow Twins
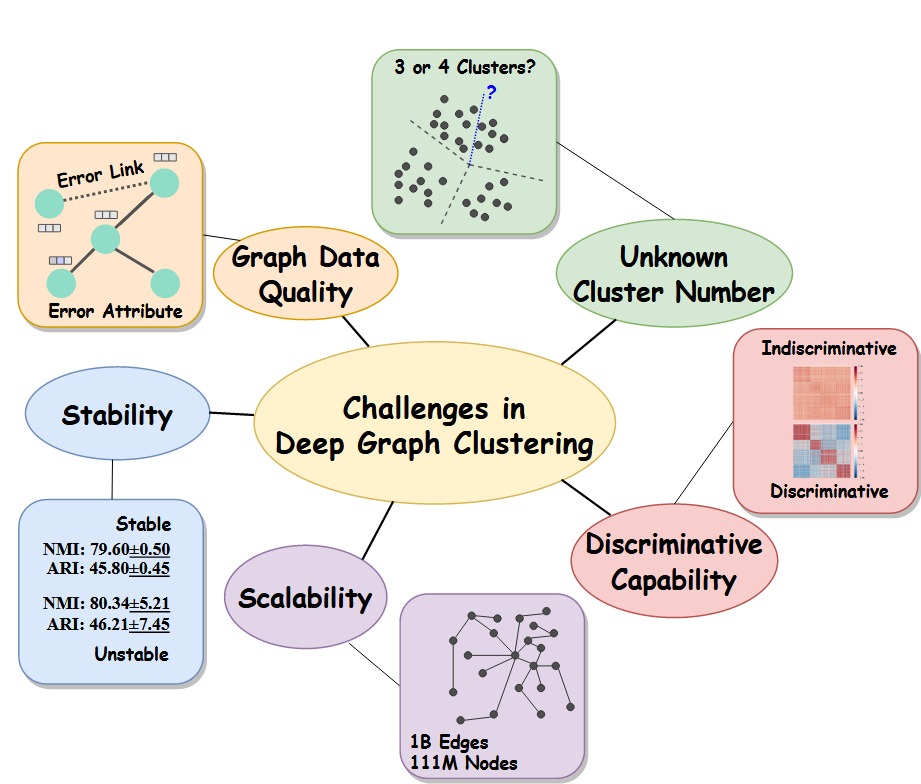
机遇和挑战
图数据质量
稳定性
很多聚类依赖于预训练和中心初始化
可扩展性
区分能力
很多深度聚类方法倾向于把节点归为一类,并且hard sample 的处理技术也缺乏
未知聚类数
正在做
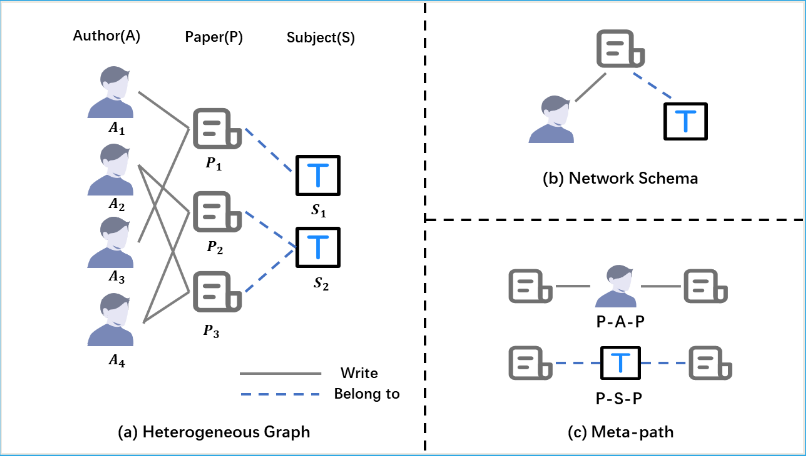
异构图
常用对比网络只对比了网络结构信息,忽视了语义信息
待做实验
- 将中心聚类改装
- 将要抄的那篇文章复现了
- 将kmeans改装
- 探测提取层的一影响
- 掌握常用的增广以及提取特征的常用用法
- 利用wandb找找参数对acc的影响
- DGCD实验